-

Why we expand information to compress it later. Many years ago I read a book called Hitchcock on Hitchcock, and one small passage in it has stayed with me longer than almost anything else I have read about films, which is one of my passions. Surprisingly, I have come to think that the ideas expressed…
-

On teaching the history of the field not as a chronology of methods but as a record of the bets we made, and lost. In January of 2023 I was in Doha, at the IEEE Spoken Language Technology Workshop, sitting on a panel with several other people who had been in the field long enough…
-

Is working on machines built by others AI research? It can be. Usually it is not… A few weeks ago I was at one of the many AI gatherings that seem to happen in New York on any given evening now. The discussion was lively and well informed: the current state of the models, the…
-

On the feedback loop that AI’s democratization left behind What happens to a technology once it stops being the property of the few who understand it deeply and becomes available to the many who simply want to use it. We have come to call this democratization, and it is, on balance, a wonderful thing. But…
-

Three kinds of work, three success criteria, and why confusing them is costly. Early in my career I worked at Bell Labs, where one could work on any intellectually challenging problem, whether or not it had immediate relevance to the mothership AT&T. Later I worked at startups where the pressure to sell and ship was…
-

Where Does the Bridge Get Built? This is the third essay in the From Spark to System series. Part I: “Why the Real AI Revolution Hasn’t Happened Yet.” Part II: “The Bridge That Was Never Built.” The previous two posts in this series built a framework. The first argued that the AI revolution most people…
-

The Bridge That Was Never Built. This is the second of three posts on innovation: what it actually is, how it differs from invention, and how technologies evolve through the construction of domains, translation into products, and the specific kind of leadership each phase requires. In my previous post I argued that the AI revolution…
-
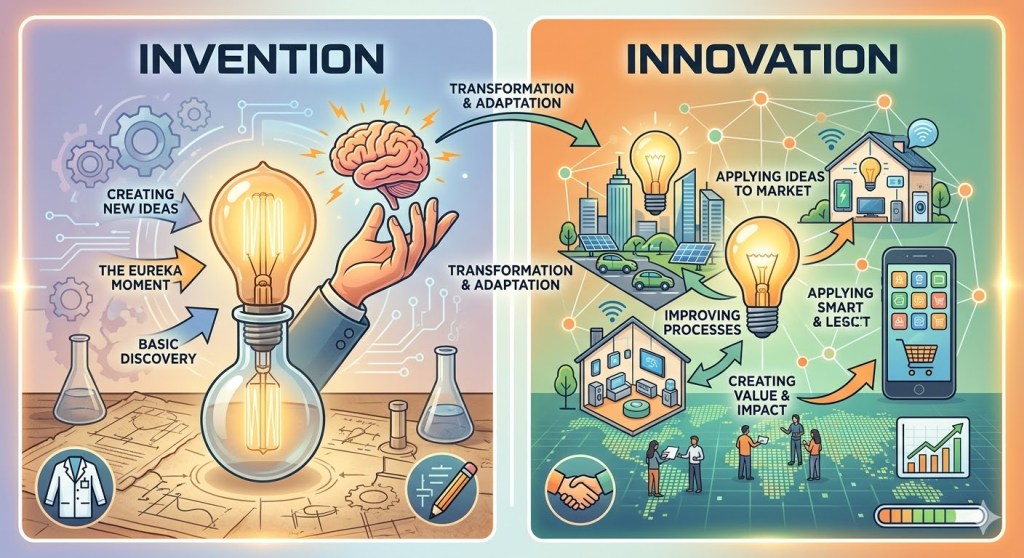
Why the Real AI Revolution Hasn’t Happened Yet. This is the first of three posts on innovation: what it actually is, how it differs from invention, and how technologies evolve through the construction of domains, translation into products, and the specific kind of leadership each phase requires. The thing everyone is calling the AI revolution,…
-
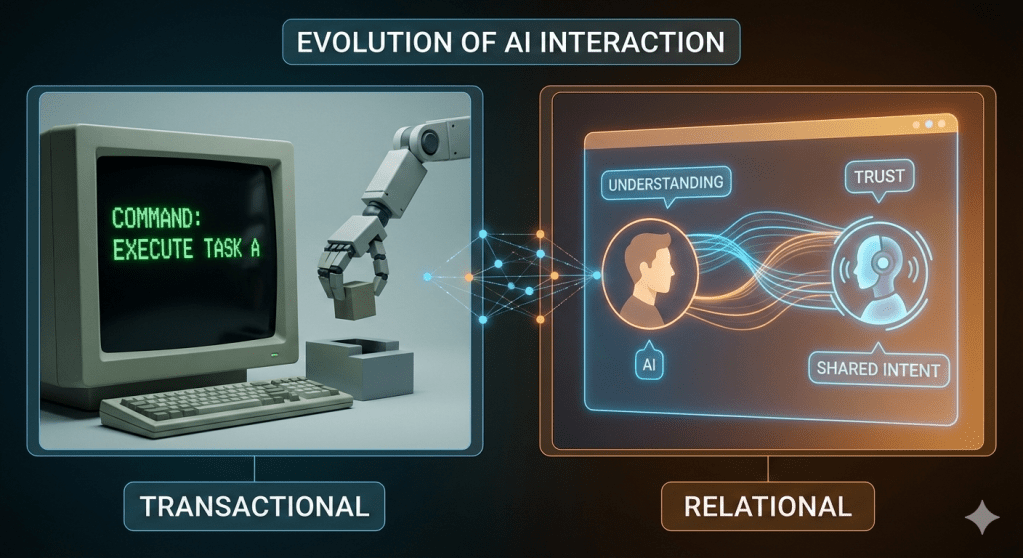
Over the years, I’ve come to see that useful AI needs more than accurate execution. It needs the ability to engage with humans over time, cope with uncertainty, and build shared understanding. This post reflects on why balancing transactional reliability with relational intelligence matters.
-

Although creating virtual assistants has long been a dream of the speech and natural language technology community—realized with the commercial launches of Siri, Google Assistant, and Alexa over a decade ago—these technologies have ultimately failed to achieve ubiquity or widespread adoption. The question is, why? In this blog post, I’ll explore the reasons behind this…
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
